이번 시간에는 동물상 대표 연예인들의 사진 데이터를 모을 것입니다.
그러나 일일이 검색하여 하나씩 다운받으려면 엄청난 시간이 걸리겠죠?
그래서 이번시간에 크롤링(Crawling)이라는 기술을 배워보겠습니다.
크롤링이란 인터넷에 있는 정보 중 우리가 원하는 것만 골라서 자동으로 수집해주는 기술입니다.
크롤링(Crawling)
= 파싱(Parsing) = 스크래핑(Scraping) = 스파이더링(Spidering)
크롤링의 기초만 할 줄 알아도 엄청 실용적이고 재미있는 것들을 많이 만들 수 있습니다.
예를 들어 학교/회사의 식당표를 크롤링하면 오늘의 식단을 볼 수 있는 서비스를 만들 수 있고 다양한 뉴스 사이트에서 원하는 주제의 뉴스만 골라서 모아 볼 수 있는 서비스도 만들 수 있겠습니다. 이런 서비스 외에도 엄청 다양한 것들을 만들어 볼 수 있겠죠?
크롤링의 원리는 매우 간단합니다.
우리가 정보를 가져오려는 사이트를 불러와서 거기서 원하는 정보를 찾고 그 정보를 가져오게하는 코드를 작성하면 끝입니다. 크롤링 고나련 라이브러리는 보통 어느 언어에나 있어서 어떤 언어를 쓰셔도 무방하겠지만 요즘 핫한 파이썬을 이용해서 실습해보겠습니다.
* 라이브러리 : 가져다 쓸 수 있게 미리 만들어진 기능
<텍스트&이미지 크롤링>
1. 환경설정
- Python 개발 환경 설정(구름IDE)
2. 예제 무작정 실행하기
- 위키피디아 크롤링 예제
3. 다른 작업에 응용하기
- 네이버 실시간 검색순위 크롤링하여 텍스트 저장
4. 완전 쉬운 라이브러리 사용
- 동물상 연예인 사진 한 방에 크롤링
Step 1. 파이썬 환경 설정하기

파이썬을 설치하고 관련 라이브러리들을 설치해야 합니다. 그런데 그냥 모두 내 컴퓨터에 설치하게 되면 나중에 다른 작업을 할때 버전 간 충돌이 발생하는 등 문제가 있을 수 있어서 보통 가상환경을 구성해서(venv, virtualenv, conda등) 거기에 설치하는 굉장히 복잡한 과정을 거치게 됩니다. 그러면 상당히 귀찮겠죠. 그래서 우리는 구름IDE를 이용하겠습니다.
구름IDE는 가상의 컴퓨터를 제공해 주는 것이라 별도의 언어 설치 과정이 필요하지 않고 또, 다른 작업 할 때는 가상컴퓨터를 새롭게 만들어서 거기서 작업하면 되므로 버전 간의 충돌도 일어날 일이 없습니다. 이런 클라우드 기반 IDE서비스를 이용하면 시간이 많이 단축되고 편리하게 개발에만 집중할 수 있습니다. 또 구름IDE는 무료로 이용할 수 있는 클라우드 IDE 서비스 중 상당히 괜찮은 편이며 혹시 불편하시다면 다른 IDE를 이용하거나 로컬 환경을 이용하셔도 무방합니다.
구름 IDE 주소는 ide.goorm.io이며 , 대시보드 버튼을 클릭하여 "새 컨테이너 생성" 버튼을 눌러줍니다.

컨테이너 즉, 우리가 사용할 가상 컴퓨터에 대한 환경을 설정하는 공간입니다.
여기서 작성한 대로 우리가 사용할 수 있는 컴퓨터가 제공됩니다.
이름 : crawling
지역 : 서울
공개범위는 public 이면 다른 사람이 와서 볼 수 있고, Private 는 나만 볼 수 있습니다.
소프트웨어 스택, 여기서 미리 가상환경에서 설치할 것을 미리 설치할 수 있습니다.
우리는 파이썬을 이용하기 때문에 파이썬을 선택하겠습니다. 이제 생성 버튼을 눌러 주세요.


컨테이너가 생성 되었으면 컨테이너 실행 버튼을 눌러줍니다.

파이썬 설치된 가상컴퓨터 환경에 들어왔습니다.
간단히 화면을 설명드리면 왼쪽에는 윈도우 탐색기 같은 탐색기가 내장되어 있고 아래쪽에는 명령어 입력창이 내장되어 있습니다. (CMD, Console 같은것)
또 파일을 열어보시면 코드를 편집할 수 있는 화면이 나옵니다.
이렇게 코딩에 필요한 화면을 한곳에 몰아 넣은 것은 통합 개발 환경, IDE라고 부릅니다. (Integrated Development Environment)
index.py 라고 해서 기본적으로 생성되어 있는데요 여기서 파일썬 코드가 잘 실행되는지 확인해 보겠습니다.
그러려면 명령어 입력창에 python index.py 를 입력해 주면 print("Hello Python")이 실행되서 Hello Python 출력된 것을 확인 할 수 있습니다.

그러면 여기에 크롤링 코드를 작성하면 되겠죠?
우리는 이번 크롤링에 Beautiful Soup이라는 라이브러리를 사용해 보겠습니다.
Beautiful Soup은 HTML및 XML 구문을 분석하기 위한 파이썬 라이브러리입니다. 굉장히 많이 쓰이는 라이브러리라서 참고할 문서들이 엄청 많습니다.

위키백과에 들어가 보겠습니다. 여기 예제 코드가 나와 있는데요. 그대로 사용해 보겠습니다. 전체를 복사해서 index.py에 넣어줍니다.

ctrl+s로 저장하시고 일단 한번 실행시켜 보겠습니다.
실행시키려면 명령어 입력창에 키보드 위쪽 버튼을 누르시면 이전 실행한 명령어가 나오고 엔터를 누르면 실행이 됩니다.

ModuleNotFoundError 떴죠. 예는 bs4라는 모듈(beautifulsoup4) 을 불러 오지 못한 건데 이는 Beautiful Soup 4 버전이 설치되어 있지 않아서 생긴 문제입니다.
설치하는 방법은 매우 간단합니다.
명령어 입력창에 pip install bs4 를 입력하시면 자동으로 다운 받고 설치까지 완벽하게 진행됩니다.
* pip = 패키지 관리자
패키지(라이브러리)를 설치하는 개념이 익숙하지 않으신 분들을 위해 간략히 개념을 설명드리면 우리가 윈도우 PC를 사용할때 발표자료를 제작해야 된다면 PPT를 다운 받아서 설치해 사용하고 문서 작성이 필요하면 Word를 다운 받아서 설치해서 사용하시잖아요 이런것처럼 윈도우에서는 이런 설치 파일을 이용해서 프로그램을 설치해서 원하는 기능을 사용하는데

마찬가지로 파이썬을 하나의 컴퓨터라고 생각을 하시면 파이썬에서 사용할 수 있는 라이브러리들이 있습니다. 크롤링에 사용할 라이브러리를 설치해서 쓰고 데이터 분석할 때는 pandas라는 걸 설치해 쓰고 이런것처럼 이렇게 어떤 미리 만들어진 기능 프로그램을 설치하여 사용할때(여기서는 패키지) 파이썬의 경우에는 파이썬 패키지 관리자 pip를 이용해서 명령어 "pip install 패키지명"만 입력하시면 자동으로 이 프로그램을 다운 받고 설치하는 것까지 모두 하게 됩니다. 이런 개념은 파이썬에만 있는게 아니고 거의 모든 언어에 다 있습니다.
Node.js에서 다루는 npm도 같은 개념입니다. 우리가 윈도우 컴퓨터를 이용할 때 윈도우에 있는 기본 기능만 사용 하는 게 아니고 당연히 이렇게 외부 프로그램을 설치해서 사용하듯이 마찬가지로 어떤 언어로 프로그램을 작성하실 때 그 언어 자체 기능으로 구현할 수도 있겠지만 같은 기능을 만들어 놓은 라이브러리가 있다면 무조건 가져다 쓰는 편이 훨씬 빠르고 효율적입니다.

이제 설치가 완료됐으니 다시 한번 실행해 보겠습니다. 이전 명령어를 가져와서 엔터하시면 결과가 나오는것을 확인하실 수 있습니다.
어떻게 이런 결과가 나왔는지 코드를 한 줄 씩 살펴 보겠습니다.
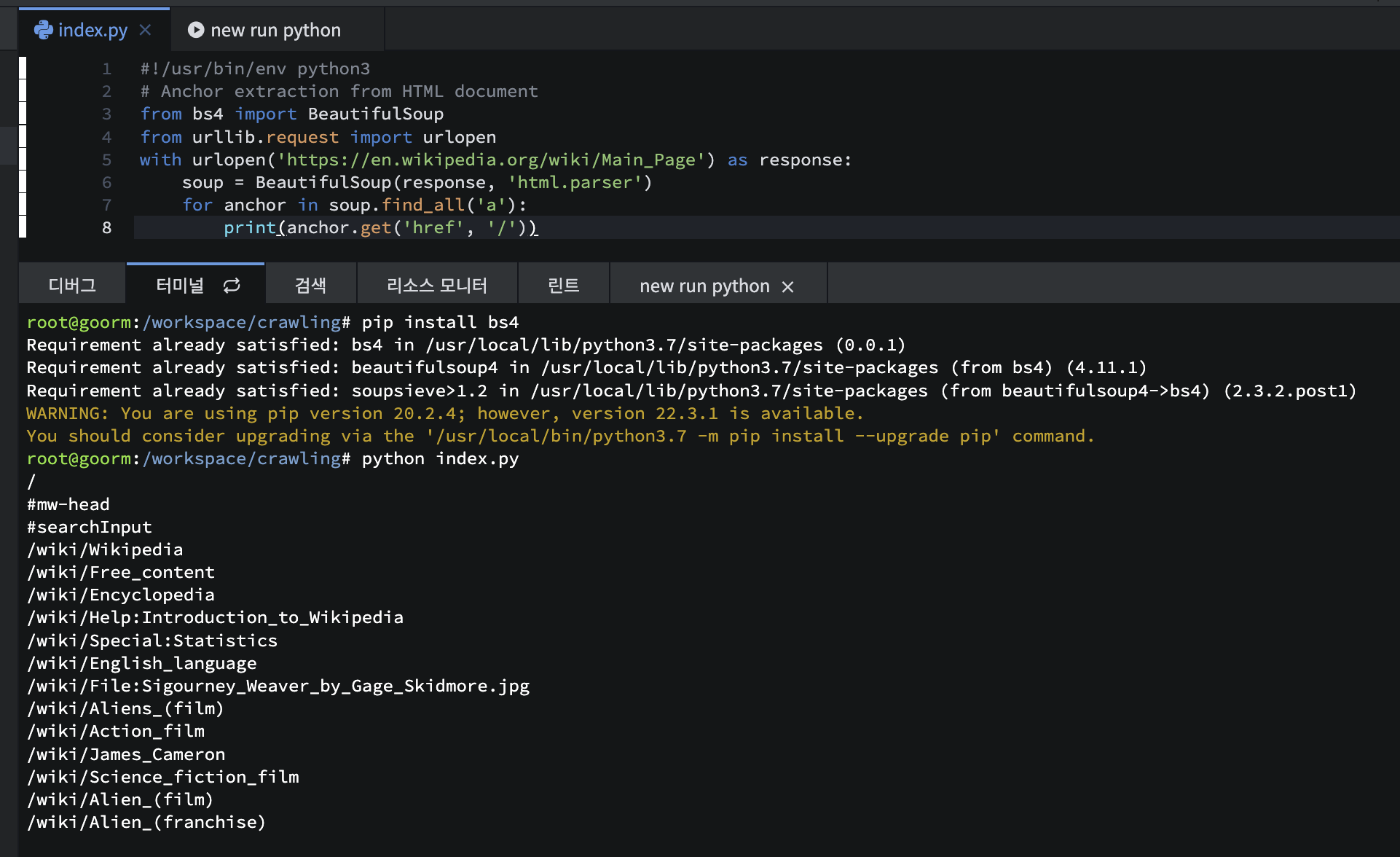
라이브러리를 불러 오는 코드입니다.
from bs4 import BeautifulSoup
from urllib.request import urlopen
그 다음 본격적인 코드가 나옵니다. 파이썬이 처음이신 분들은 with ~ as 구문이 좀 익숙하지 않으실 것 같은데요.
조금 더 직관적으로 바꾸면 response = urlopen('https://en.wikipedia.org/wiki/Main_Page') 로 쓸 수 있습니다.
soup = BeautifulSoup(response, 'html.parser') response로 가져온 값을 'html.parser'로 분석을 한 다음 soup 변수에 담아 줍니다.
반복문을 이용해서 soup 중에 'a' 태그를 찾아서 anchor라는 변수에 넣습니다.
for문 마지막에에 : 다음 들어쓰기를 하면 계속 반복 되는 문장입니다.
하나씩 가져온 anchor중에 href 즉, 주소를 가져와서 print 하라는 기능입니다.
with urlopen('https://en.wikipedia.org/wiki/Main_Page') as response:
soup = BeautifulSoup(response, 'html.parser')
for anchor in soup.find_all('a'):
print(anchor.get('href', '/'))
그러면 이 코드가 어떻게 동작하는지 실제 이 사이트에 들어가서 확인해 보겠습니다. 아까 작성된 url에
실제로 들어왔습니다. 여기서 개발자 도구를 열면 HTML 코드를 이렇게 볼 수 있습니다. 여기 태그들 중에서 아까 .findAll('a')해서 <a>태그 가져와서 이 중에 "href" 부분을 출력하는 코드가 있었습니다.

쪽 출력된 것을 볼 수 있죠.

이제 이런 흐름이 어느 정도 이해가 되시죠.
pip install google_images_download
Reference
https://www.youtube.com/watch?v=ZTJjW7XuHIY&list=PLU9-uwewPMe2-vtJAgWB6SNhHcTjJDgEO
https://www.youtube.com/watch?v=1b7pXC1-IbE&t=0s
'11. 수익형 사이트 > >> 조코딩 동물상테스트' 카테고리의 다른 글
| 웹캠 없이 Teachable Machine으로 나와 닮은 동물상 찾기 | 수익형 웹, 앱 만들기 2강 (0) | 2022.12.28 |
|---|

댓글